Frequent Pattern Compression
Frequent Pattern Compression: A Significance-Based Compression Scheme for L2 Caches( 原文链接)。随着处理器和内存速度之间差距的扩大,内存系统设计人员可能会发现缓存压缩有利于增加缓存容量和减少片外带宽。大多数硬件压缩算法都属于基于字典的类别,这依赖于构建字典并使用其条目对重复数据值进行编码,在压缩大数据块和文件时非常有效。然而,cache line通常为32-256 bytes,每行字典的开销很大,这限制了这种算法的可压缩性,并增加了解压缩延迟。对于这样的短行,基于重要性的压缩可以考虑。
本文提出并评估一种简单的基于重要性的压缩方案,该方案具有较低的压缩和解压缩开销。该方案使用带适当前缀的压缩格式存储常见的word模式,从而按word逐行压缩cache line。提出一种压缩缓存设计,其中数据以压缩形式存储在L2中,但在L1中未压缩。L2被压缩到预先确定的大小,以减少解压开销。
基于重要性的压缩基于这样的观察:大多数数据类型(例如,32位整数)可以存储在比允许的最大位数更少的位中。即窄值与0值大量存在。与基于字典的压缩方案相比,基于重要性的压缩不会产生每行字典开销,这使得它更适用于典型的短缓存行。此外,压缩和解压硬件比基于字典的编码和解码要快。然而,对于长缓存行,可压缩性可能会显著降低。
Frequent Pattern Compression
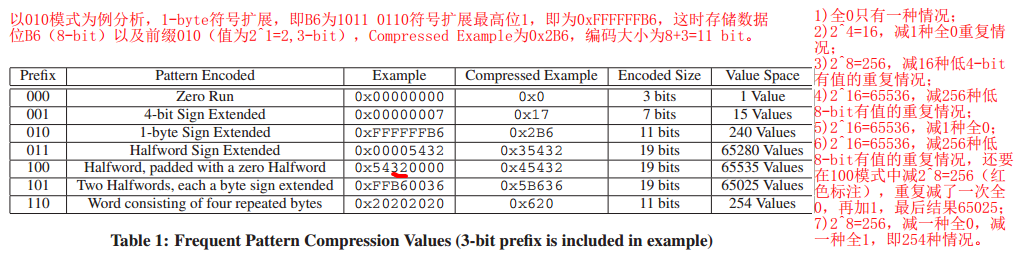
每个cache line被分成一些32-bit大小的word(例如,64-byte的cache line分成16个word)。表1显示了每个前缀对应的不同模式。这些模式是根据许多商业基准测试中的高频模式选择的。每个32-bit的word都根据模式表被编码为一个3-bit前缀加上数据的压缩格式。 与这些模式都不匹配的word以其原始的32位格式存储。如果某个word与表1前七行中的任一模式匹配,则将其编码为压缩格式。
Segmented Frequent Pattern Compression
与未压缩相比,L2 cache必须能够在相同的空间中容纳更多的压缩cache line。这就会导致原本的线性映射被破坏,或者产生碎片可利用空间。最常见的解决这一问题的办法是解耦缓存访问,在address tag与data storage之间添加间接层。
理论上,cache line可以压缩成任意数量的bit。然而,这种设计增加了缓存管理的复杂性。本文的压缩缓存设计中,每个缓存行存储为一组8-byte segemnt。例如,64-byte的cache line一定能够被存储为1-8个segment,未压缩为8个8-byte segment。压缩的cache line,填充0,直到其大小变为段大小(8 byte)的倍数,这些额外的0(与任何tag不对应)在解压缩期间被忽略。虽然这种方法可能在某些模式下不具有高压缩比,比如,全0的情况下,但是它能够更快地实现缓存访问。
Compression and Decompression
本文提出了一种压缩缓存设计,其中未压缩数据存储在L1中,压缩数据存储在L2中。这有助于减少许多阻碍性能的L2缓存缺失,同时不影响L1缓存的命中。然而,这样的设计增加了在两个级别缓存之间移动时压缩或解压的开销。而FPC能够尽可能降低压缩与解压开销。
Compression
cache line压缩发生在数据从L1写到L2时。使用一个简单的电路(并行地)检查每个word的模式匹配,如果一个word匹配七个可压缩模式中的任何一个,就使用一个简单的编码电路将word编码成最紧凑的形式。如果没有找到匹配项,则将整个word存储为前缀“111”。对于zero run,需要检测连续运行的零,并递增第一次出现的数据值来表示它们的计数。由于本文的设计中zero run被限制为8个零,这可以在一个循环中使用一个简单的多路复用器/加法器电路来实现。cache line压缩可以在内存管道中实现,方法是在L1到L2的写路径上分配三个管道阶段(一个用于模式匹配,一个用于zero run编码,一个用于收集压缩行)。一个包含少量压缩和非压缩形式条目的小受害者缓存可以用来隐藏L1写回时的压缩延迟。
Decompression
当数据从L2读取到L1时,会发生cache line解压缩。解压延迟非常重要,因为它被直接添加到L2 hit延迟中。解压缩比压缩慢,因为cache line中所有word的前缀都必须按顺序访问,因为每个前缀用于确定其对应的编码word的长度,从而确定所有后续压缩word的起始位置。
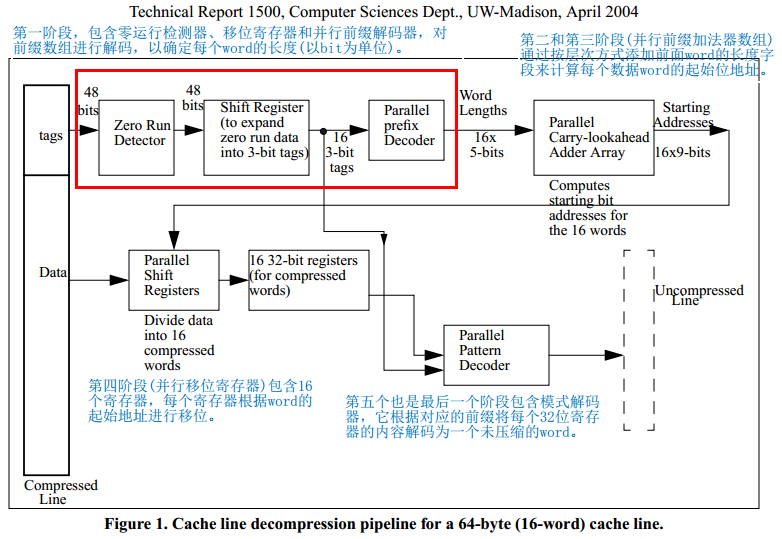
下图展示了一种可用于解压64-byte cache line的五阶段硬件管道。
原文作者: malizhen
原文链接: http://malizhen.github.io/2019/07/01/Frequent Pattern Compression/
版权声明: 转载请注明出处(必须保留原文作者署名及原文链接)